
Introduction
During a recent assessment, we identified a server running Nexus Repository 3 that was vulnerable to CVE-2024–4956. This led to us pillaging data from the system and ultimately extracting Apache Shiro 1 SHA-512 password hashes to the web application from this data. Apache Shiro’s version 1 SHA-512 hashing implementation involves salting the input data with a secure, randomly generated value and performing the hash operation iteratively (typically thousands of times) to enhance security against brute-force attacks. In simpler terms, it is a salted, iterated SHA-512 hashing mechanism. In this post, I’ll describe the steps taken to identify the hashing algorithm and how I created a Hashcat module capable of cracking it. This will guide you through the process of creating a custom module to effectively crack these hashes.
Sonatype Repository 3
Before we continue, it’s important to note that the Apache Shiro 1 SHA-512 algorithm is used by Sonatype Repository 3 to hash user credentials for the web application database, as of the time of writing. Since there is a public mirror of the code base available on GitHub, it is possible to view exactly how the application hashes credentials. You can clone the repository from the following URL. If we clone that repository and do a recursive grep command for the text “shiro.crypto”, we will get the following results shown below.

Out of these results, the file responsible for performing password hashing is DefaultSecurityPasswordService.java, which can be accessed here. We can look at the relevant parts of the file below.
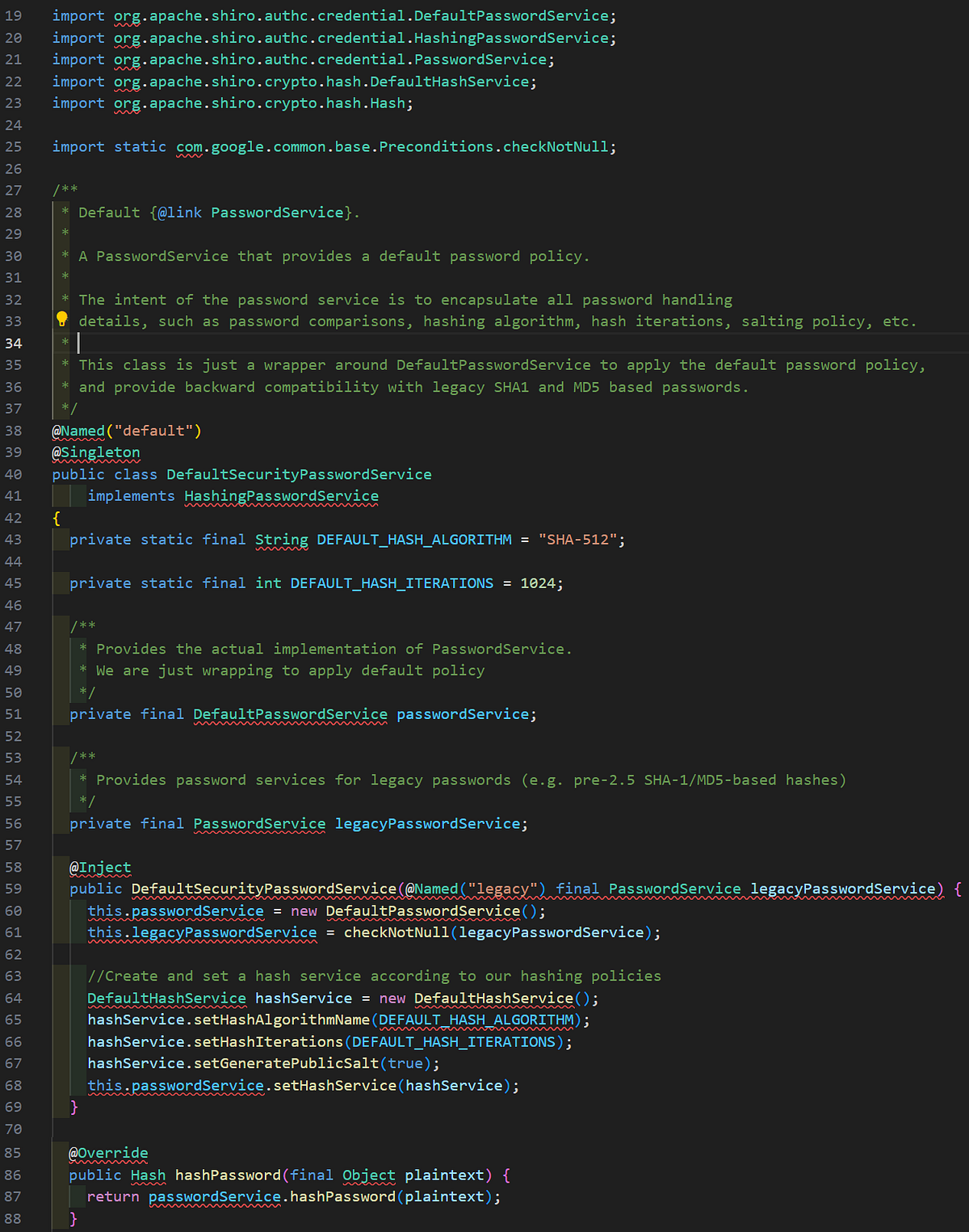
The key pieces of information to take away here are the hash algorithm (SHA-512), iterations (1024), the constructor for the class, and the hashPassword method. We can see in the constructor that the passwordService member (of type PasswordService) is set to a new instance of the DefaultPasswordService class. A new DefaultHashService object is created, then configured with the hash algorithm and iterations. The passwordService member then calls the setHashService method using the hashService object. The hashPassword method simply calls the hashPassword method of the passwordService member. The relevant code for the DefaultPasswordService class is shown below and can be accessed via the following URL.
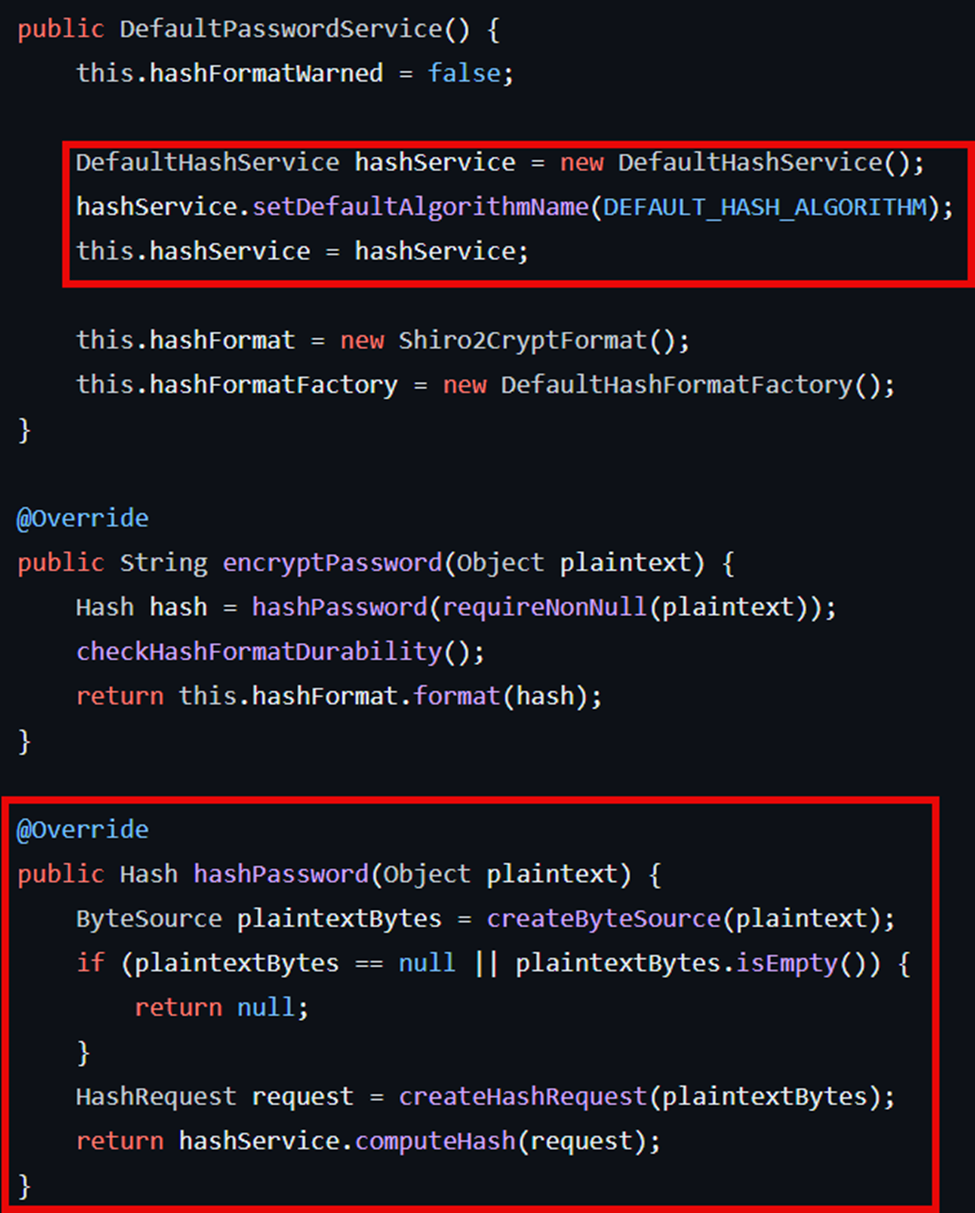
Here we can see the default constructor sets up the class using some defaults, which have been overridden with a custom HashService class object previously shown. We can also see the implementation of hashPassword, which ultimately ends up calling computeHash of the hashService member (of type DefaultHashService). The implementation for computeHash in the DefaultHashService class can be seen below and accessed at the following URL.

We can see there is an attempt to obtain a HashSpi object using the algorithm name, which if successful will call the newHashFactory method on the object, followed by the generate method and return the result. The SHA-512 algorithm will end up creating a new SimpleHashFactory and using its generate method. The generate implementation is shown below and can be accessed at the following URL.

The generate method will ultimately end up calling createSimpleHash, which creates a new SimpleHash class object using the algorithm name, sets the iterations, salt and returns it. The relevant parts of the SimpleHash class are shown below and can be accessed here at the following URL.

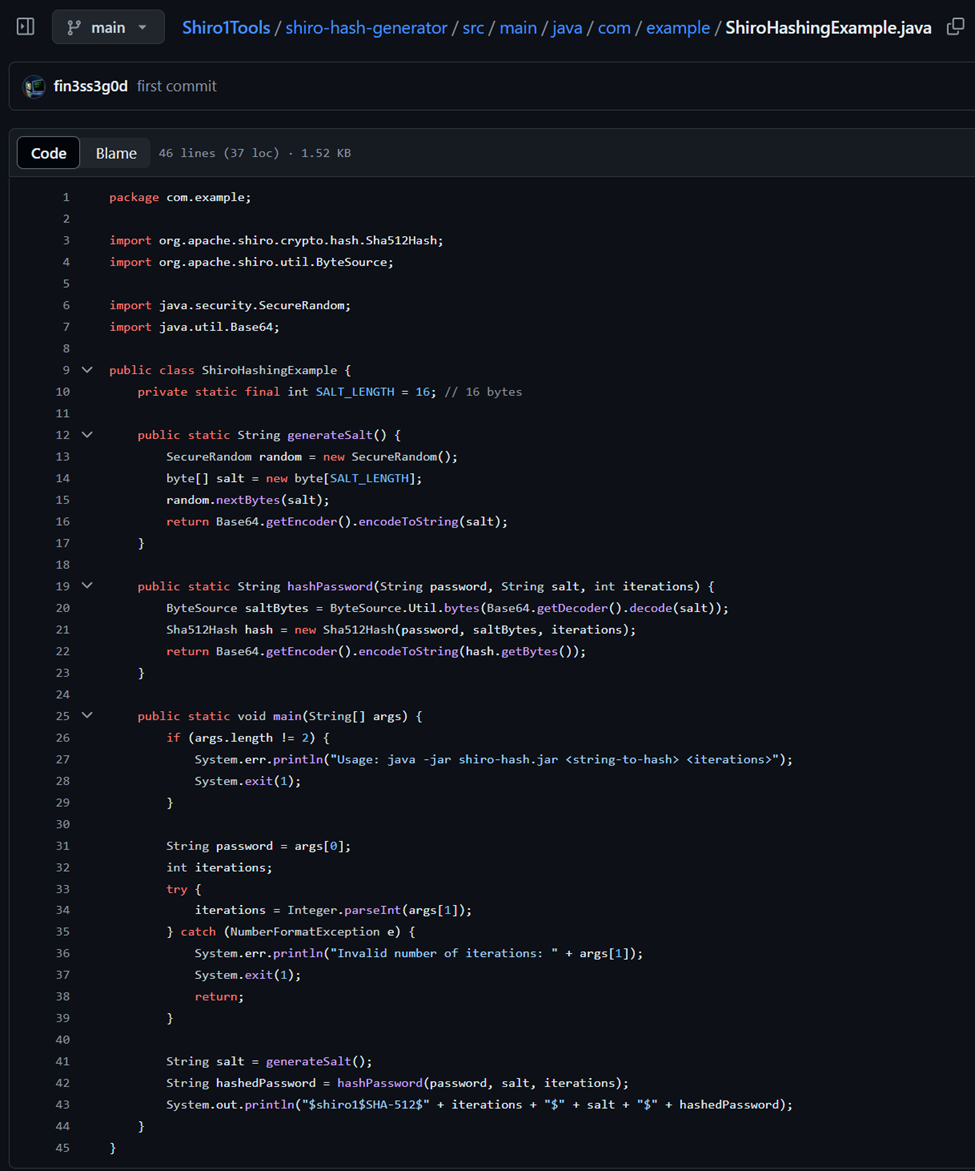
We can see the constructor sets the algorithm to be used for future hashing, with the core hashing methods being setBytes and hash, and hash having multiple overloads. The main cryptographic operations involve creating an initial hash using the salt and password bytes, then repeating the hashing process using the previous digest until the iteration count has been reached. Another example of creating an Apache Shiro 1 SHA-512 hash using Java is available in this repository and can be seen below.
Previous Research
At the time of our assessment, cracking support was very limited with not much information about cracking the algorithm available on the Internet. Searching the title, body, and comments of all Hashcat issues had no mention of the hashing implementation, almost as if it didn’t exist. We were able to come across one post on the Hashcat forum here from 2016, which seemed to be the only mention of it by anyone associated with Hashcat. It is also discussing a SHA-256 version of Apache Shiro 1, not to be confused with what our research is focused on, which is a SHA-512 implementation.

At first, I found this to be confusing because there are plenty of salted and iterated hashes supported by Hashcat in 2024. Thinking about it further, the only explanation I can think of is that in 2016 at the time of the post, Hashcat did not have the capabilities to crack a salted and iterated hash of this nature. The Hashcat kernel structure in 2024 is actually designed around iterated hashes, forcing an author of a kernel to implement a method in the kernel called loop where the iterated cryptographic work is done.
Additionally, although there were a couple gists written in Java and C floating around, the cracking performance left more to be desired as both of these examples run on the CPU.

Wanting to increase cracking performance by taking advantage of a multiple GPU hash cracking rig as well as Hashcat features such as advanced rule support, this led to the journey of creating a custom Hashcat module for the Apache Shiro 1 hashing implementation.
Creating the Hashcat Module

Initial Thoughts
Looking at the standalone C cracking implementation, it’s apparent that creating a Hashcat module for this hashing implementation should be straightforward, or at least the core cracking logic was already laid out for me. It is an iterated SHA-512 hash with a salt. Could this be that difficult to crack to the point where Hashcat maintainers decided they wouldn’t create a module altogether? Surely, it couldn’t be, could it? I can think of more computationally demanding algorithms for certain. So, why hadn’t it been done before? Has there never been enough of a need/demand? I never got an answer to these questions throughout this research, but we got the module we wanted so I guess it doesn’t really matter anyways. Looking at some of the Hashcat OpenCL code, there were even libraries for the SHA-512 algorithm. Everything that was needed to create the module was already contained within the repository. My confidence level began to rise for being able to create a working module.

First Steps
Before we get started, you can access the module in my Hashcat fork here with module 12150 (will require building from source) and follow along with code discussion.
You will notice if you try to research the topic of creating a Hashcat module, not much exists outside of the Hashcat repository itself. I was able to find this blog from 2020 which was helpful but did not cover creating an OpenCL kernel from scratch, which was necessary in our case. The Hashcat repository has extremely thorough documentation for creating your own module (also called a plugin by Hashcat developers) available here, and it is official documentation/advice from the developers themselves. It is a full-blown guide walking you through the entire process of creating your own module and gives you some necessary prerequisite knowledge. Using this guide, if you have the necessary C programming knowledge to implement the algorithm you will be able to create your own module fairly easily. More advice would be to remain patient when you are going on this journey, do not expect instant results on the first day. There is a learning curve associated with this task and you have to learn the lay of the land first before you can have success creating a module. If you study the plugin development guide, it will give you all of the necessary information you need to create your own module.
Ultimately, we will be creating two files which will be the module C code file and the OpenCL kernel code file. The module C code registers the module with Hashcat itself and handles everything except for the raw cryptographic operations of the algorithm you are trying to implement. The raw cryptographic operations are implemented in the OpenCL kernel file. This is a brief explanation while the plugin development guide goes into much further detail. We will start by covering the module C code.
Creating the Module C Code

Background and Beginning of Module
The beginning of the module is setting up some necessary configurations that will modify the behavior of the module and will instruct Hashcat how to operate. The beginning of the Apache Shiro 1 module is shown below.
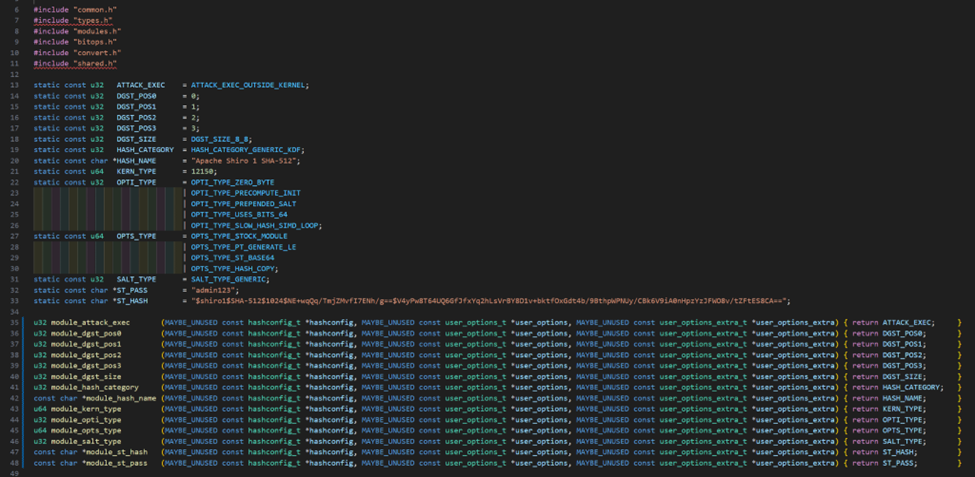
Every Hashcat module will follow the same structure in the beginning of its code, and each of the methods shown above are mandatory for every module to implement as they provide Hashcat the necessary information it needs to run the module. A module can also implement other methods that aren’t required or shown above. You can find the documentation for each of these methods below:
· module_dgst_pos0 — module_dgst_pos3
Below are some snippets of the documentation for module_opti_type and module_opts_type.

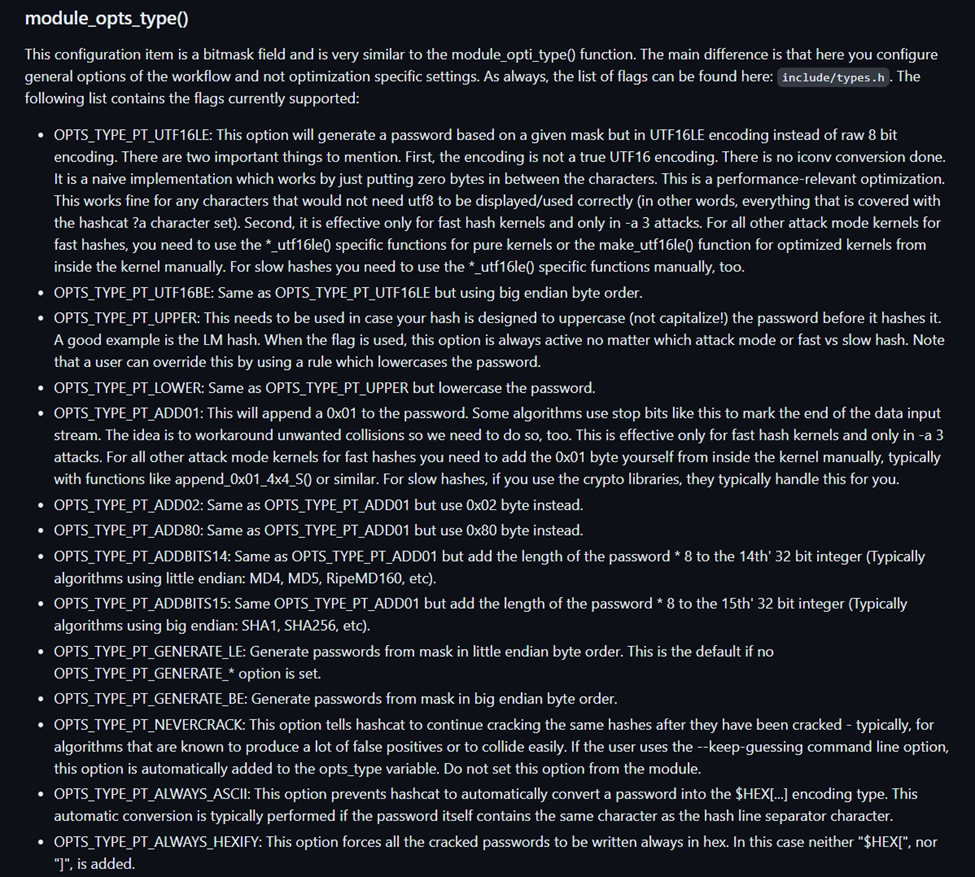
Remaining Methods
In order to complete this module, there were only five more methods to implement:
· module_tmp_size: Returns the size of the tmps structure
· module_pw_max: Returns a size that is the maximum length for any given password this algorithm produces
· module_init: Register all the functions that you have programmed by assigning it to module_ctx, initializing the module
The tmps Structure
An important structure to explain at this point would be the tmps structure, which has a definition of: “void *tmps: This is the generic context buffer. It is available only in slow hash kernel mode. In slow hash mode you want to read and write this buffer. There is one entry for each work item.“ Not to get ahead of ourselves before we talk about the kernel in more depth, but below is more context on the tmps structure on the kernel side of things.

We’ll talk more about this structure later as it is a significant part of the module. At this point, we would then begin developing the five methods listed above assuming our mandatory methods are in place. Below is an example of our tmps structure along with the implementation for module_tmp_size and module_pw_max.
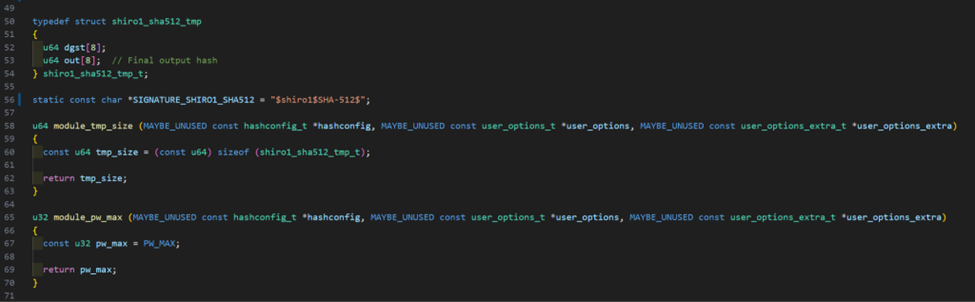
We define our tmps structure in the module C code and return its size in the module_tmp_size method so the kernel knows its size and how large of a buffer to allocate for the structure. The structure can be broken down as follows:
· dgst: Temporary hash digest buffer
· out: Final output hash to use during comparisons
The module_hash_decode Method
This brings us to the module_hash_decode method which can be described as: “The decoder function is the function that is called again and again for every line in your hashfile. We also call this sometimes the hash parser. Here you have to program the logic which decodes the line into its components and then stores them in the standardized data structure which hashcat understands.“ The method can be described as accomplishing the following goals shown below.
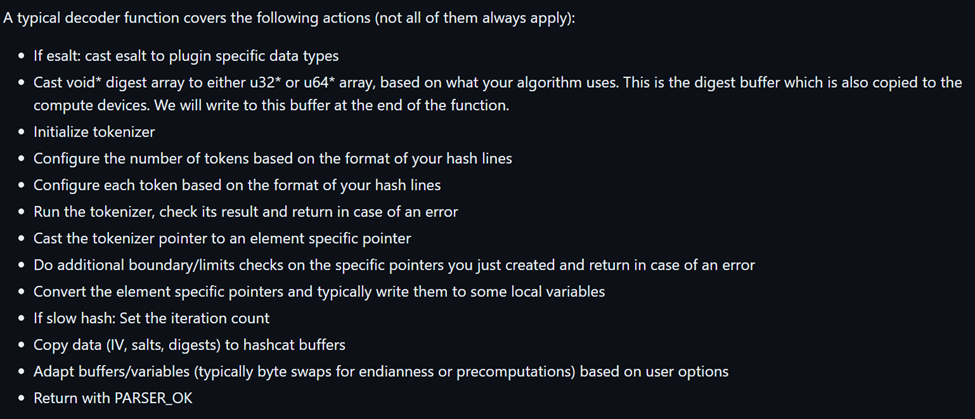
The above might sound like a lot, but in our case it’s really not. The tokenizer is a means of extracting the necessary data from each hash string we decode during this method such as the salt and hash bytes. Here’s an example of our module_hash_decode method below.

With the salt, hash, and iteration data extracted during the tokenizer phase, we can then prepare the salt and digest buffers as shown below which finishes the method.
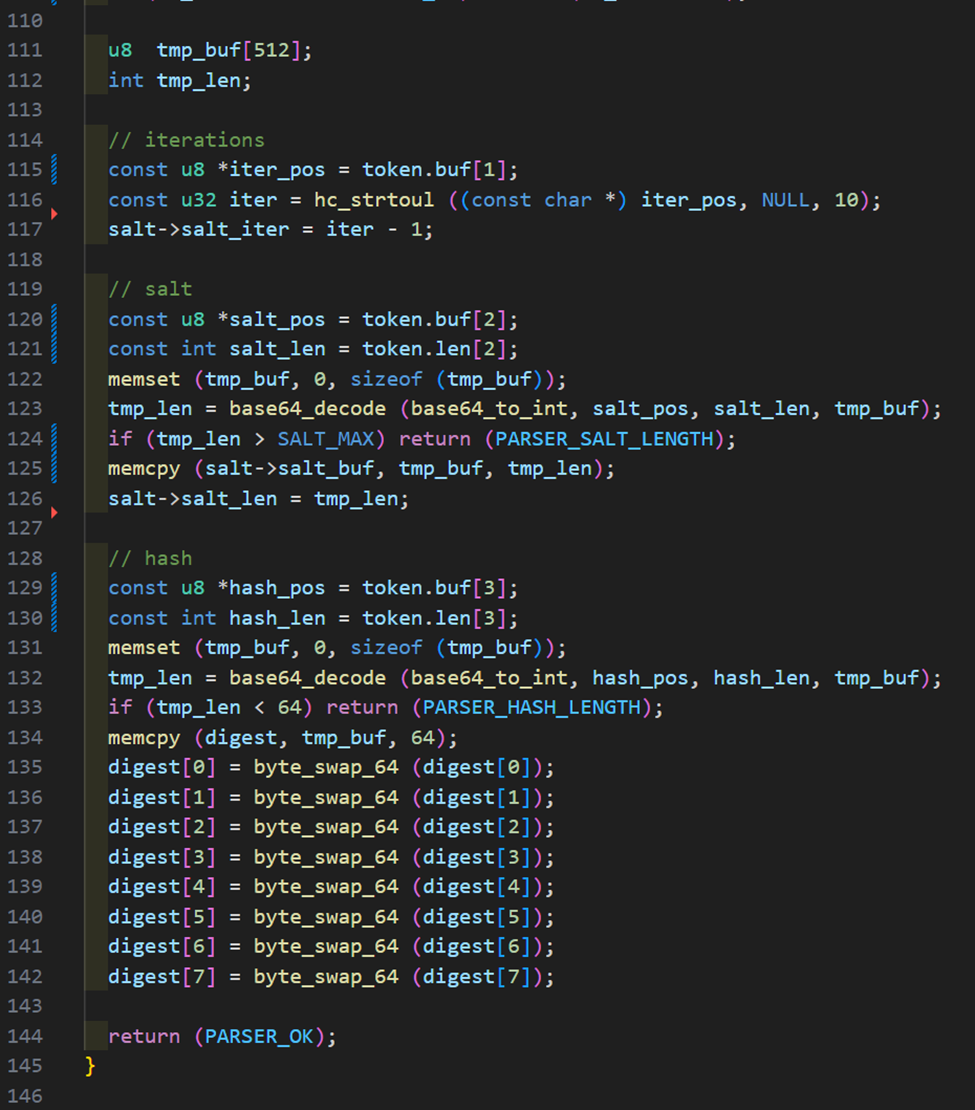
At this point, the salt buffer is prepared with the salt bytes and iterations. The digest buffer containing the hash bytes is also prepared which is used in hash comparisons. For example, the kernel will generate a hash based on an entry in a wordlist and compare that hash to this one. If they match, you know you cracked the hash. Be aware that you will need to manually manage endianness throughout this process, hence the byte swap shown above. In this case, we needed to convert the raw buffer bytes to 64-bit integer format for storing the digest. This is how the final digest is stored by the Hashcat crypto library in our case for SHA-512.
The module_hash_encode Method
The next method implemented in the module is module_hash_encode which can be explained as seen below.
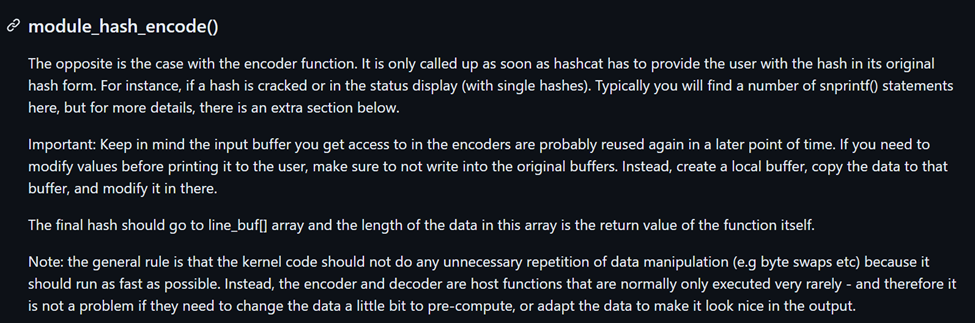
The implementation is shown below, in this case we could simply use the original hash buffer that was read from the input hash file.
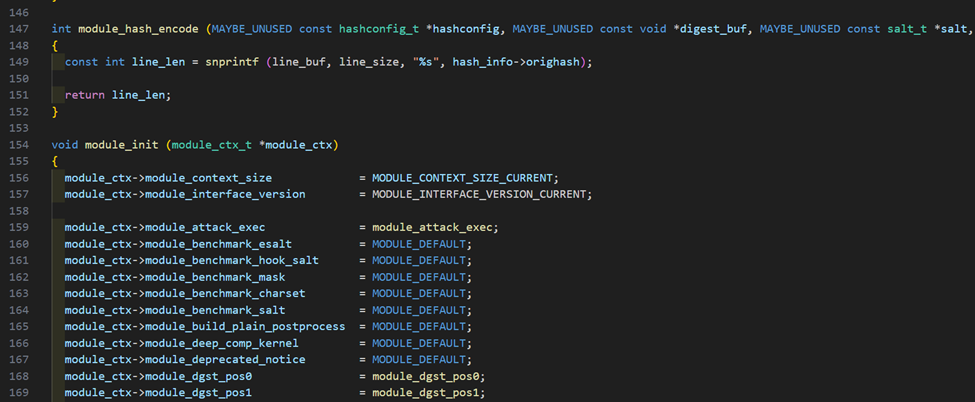
Wrapping Things Up
The last method to implement was module_init which can be explained as shown below.

I won’t show the implementation for our module, but it is straightforward, and you can find plenty of examples throughout the Hashcat source code as every module has it implemented. At this point, we are ready to jump into the kernel code!
Creating the Kernel

As previously mentioned, the second file we are required to create is the OpenCL file which is our kernel. Shown below is some introductory information about the kernel from the Hashcat documentation.
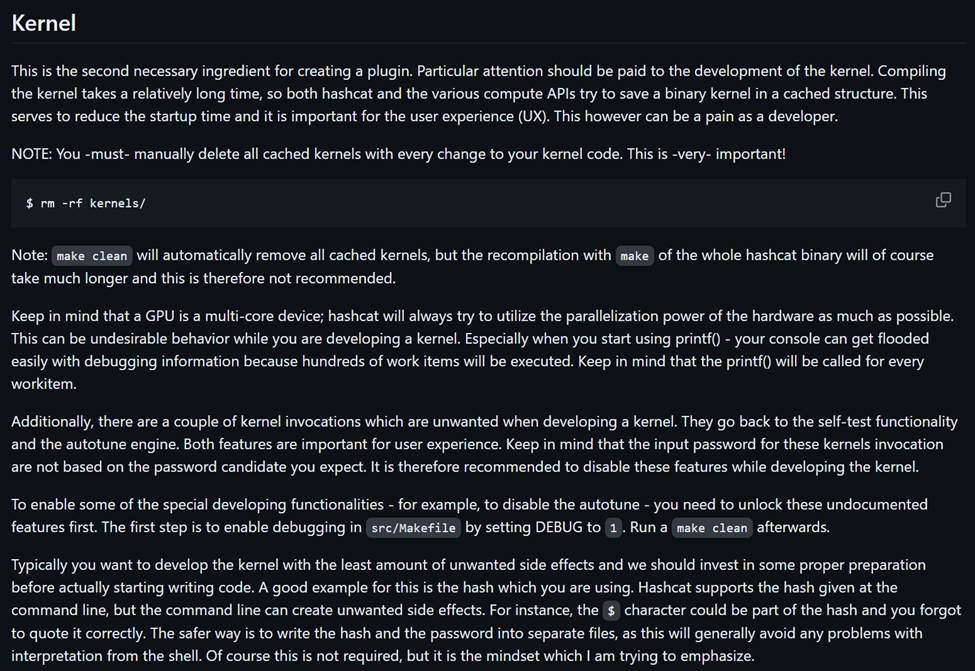
Before we continue any further, let’s take a step back for a second and talk about what OpenCL is and what an OpenCL kernel is. We will refer to the overall OpenCL file as a kernel as well as individual methods inside of the file. Hashcat uses OpenCL (Open Computing Language) for its kernels, which are the core components responsible for performing the actual hash computations. The .cl file extension indicates OpenCL source files.
What is OpenCL?
OpenCL is a framework for writing programs that execute across heterogeneous platforms, including CPUs, GPUs, and other processors. It allows developers to write code that can run on different types of hardware, making it versatile for high-performance computing tasks.
Kernel Programming in OpenCL
C-like Syntax: The syntax of OpenCL kernels is very similar to the C programming language. This is because OpenCL is based on a subset of ISO C99, with some extensions and restrictions to accommodate the parallel nature of the hardware it targets.
Parallel Computing: OpenCL is designed to exploit the parallelism of GPUs and other hardware accelerators. This makes it highly suitable for tasks like hash computation, which can benefit from being parallelized.
Components of an OpenCL Program
Host Code: Written in a standard programming language like C or C++, the host code sets up the OpenCL environment, compiles the OpenCL kernel code, and manages data transfer between the host and the device.
Kernel Code: Written in OpenCL C, this code runs on the OpenCL-compatible device (such as a GPU). The kernel code is what you see in the .cl files.
OpenCL Background Summary
Before starting this journey, I was a complete noob to OpenCL, so I thought leaving this information here would be beneficial for anybody attempting to go down this path. Since we are trying to create a kernel for the module, it is helpful to know how it works from a technological perspective. Now that we know what we are dealing with, let’s dive into the implementation.
Hashcat Kernel Background
Shown below is documentation from Hashcat explaining what a slow hash type kernel is, along with information about the three methods you need to implement inside the kernel. This documentation can be accessed here. The Apache Shiro 1 kernel is a slow hash type kernel due to the algorithm being so demanding that the PCI Express Bottleneck is no longer relevant as it is with fast hash types. This is largely due to the fact the hash is iterated.

Below is further documentation about the three kernels and the sequence in which you will typically interact with the tmps context buffer.
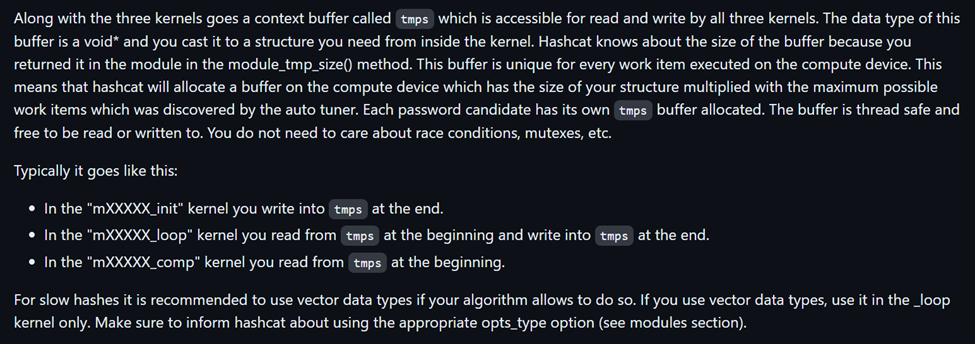
Another important thing to know when developing your kernel is what macro you should use for each of the methods. A list of the macros can be seen below and accessed here. The Apache Shiro 1 module will use the KERN_ATTR_TMPS(t) macro for all of the kernels since they only use a tmps structure.

The last important thing you will need to know when developing a kernel are the kernel parameters (documentation link shared above). As discussed previously, OpenCL programs allow data transfer between a host and a device. All of the parameters you see below are accessible to every kernel. A good example of this is how we extracted the salt in the module C code during the module_hash_decode method. This ends up going in a buffer called salt_bufs. The buffer is then passed to the kernel so the kernel code can interact with the salt. Once we start going through the kernel code for the Apache Shiro 1 module and you see some working examples, these will start to make more sense. A snippet of the kernel parameters Hashcat documentation is shown below.

At this point, now that we understand the structure of a kernel, the three methods that we need to implement and what their purposes are along with some necessary prerequisite knowledge, we are ready to begin developing the kernel.
The init Method
In order to understand what we need to do in this method, we can refer to the standalone C cracking implementation for inspiration here.

The piece of code highlighted above is what we will ultimately need to replicate in our init method of our kernel. This will create an initial SHA-512 hash digest using the salt and password. How we can replicate this in our init method of our kernel is shown below.
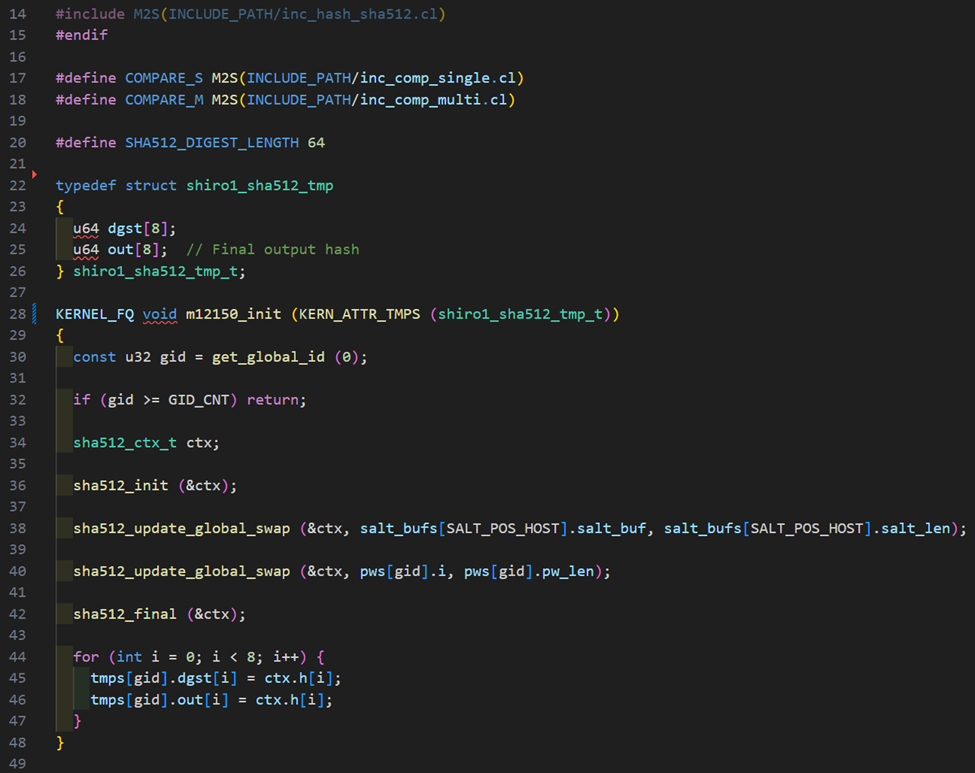
Let’s break this down a little bit. Firstly, we are using a pre-existing Hashcat helper file for SHA-512 (inc_hash_sha512.cl) which already contains the necessary methods we need for the kernel of this algorithm. This is where all of the sha512 prefixed methods are coming from as well as the sha512_ctx_t structure. Overall, the method should look really similar to the OpenSSL standalone C cracking application. A question you might have is what is going on with the swap methods? In this particular case, we are converting data between 32-bit and 64-bit integer format as required by the algorithm, which really comes down to how the structures and methods for the cryptographic operations want the data. After updating the sha512_ctx_t structure with the salt and password, we call sha512_final and update the tmps dgst and out buffers with the resulting hash digest. We are now ready to implement the loop method.
The loop Method
As shown earlier, this method is where the iterative cryptographic work will take place since this is an iterated hash algorithm. In this case, we will continue creating a new hash based on the previous hash value until the iteration count is reached. The code highlighted from the standalone C cracking application can be used as inspiration for what we will need to implement.
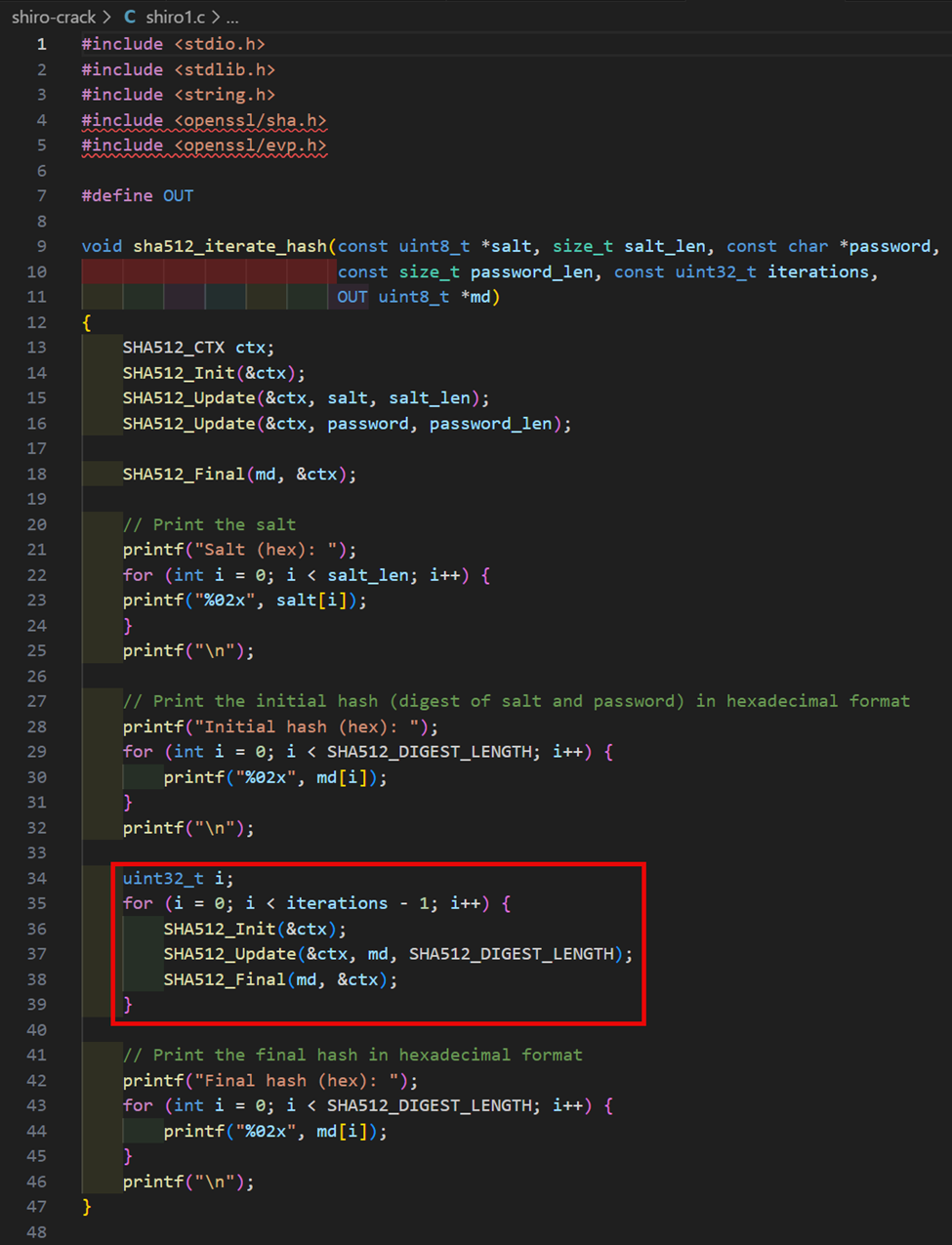
The relevant portions of the implementation for the kernel loop method are shown below.
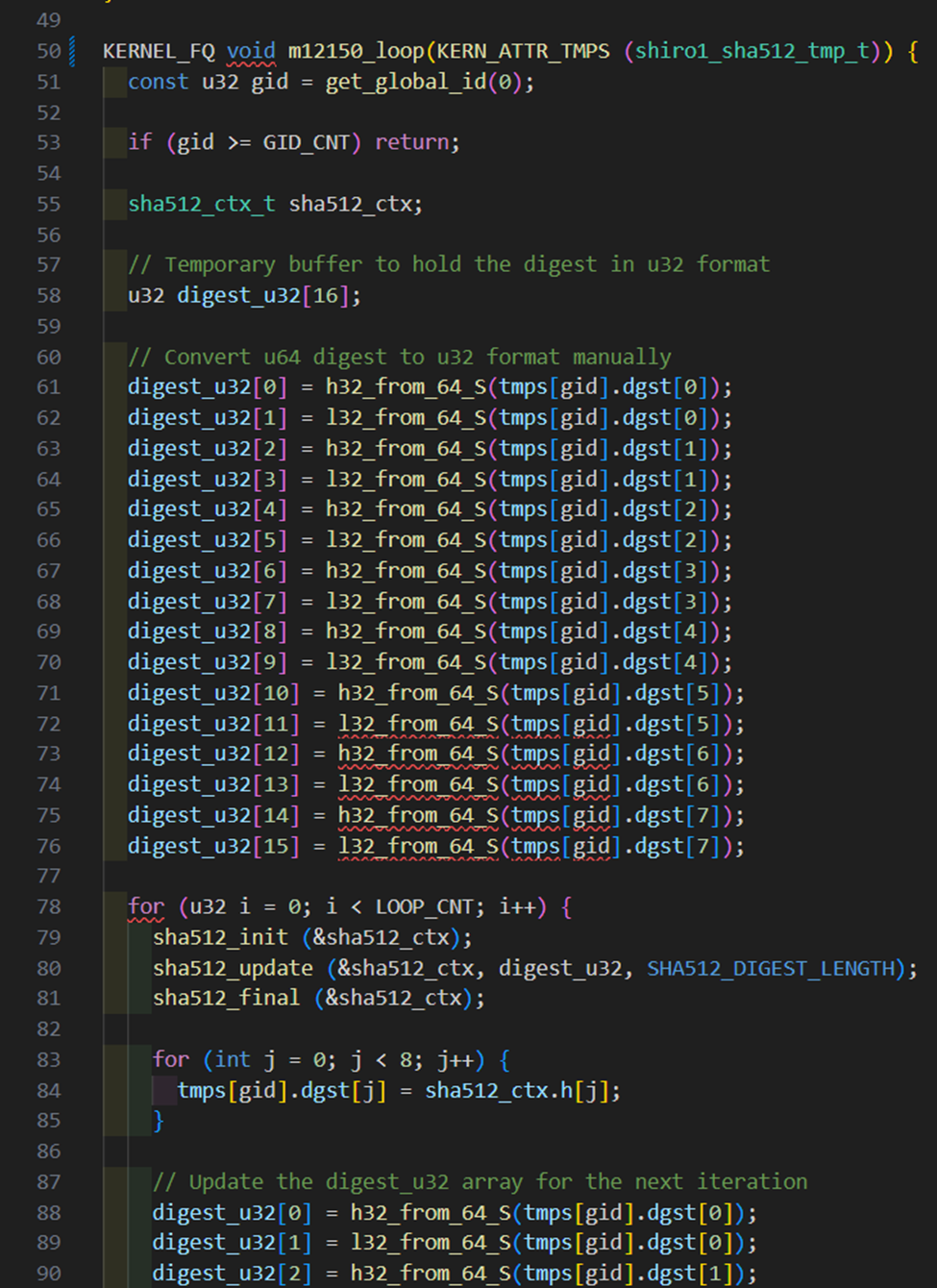
In the beginning of the method, we convert our hash digest contained in the tmps dgst buffer from u64 to u32. This is because the sha512_update method is expecting our data to be in u32 format and if we try to use the u64 data by performing a simple cast, we will produce inaccurate hashes due to the cryptographic operations being performed on data which is not in the expected endianness. We then perform the hashing loop, similarly to the standalone C cracking example. In this case, LOOP_CNT instructs the method how many times to perform the iterative cryptographic operations. Once LOOP_CNT equals the total number of times the hash was supposed to be iterated, the comp method will be called. At the end of the method, we update the out buffer of tmps with the last generated digest which will be used for the comparison in the comp method.
The comp Method
This method performs the hash comparison logic, which will essentially check to see if the produced hash from the kernel matches the target hash digest we are trying to crack. The standalone C cracking example simply used memcmp to check and see if the target digest buffer equaled the generated hash buffer. Hashcat has a much more sophisticated way of performing hash comparison which utilizes a bloom filter and an additional binary tree search. An explanation of this can be seen below.

As mentioned above, we will follow suit on how to use the COMPARE_M macro. We will assign the final digest to r0 — r3 which needs to be in u32 format, then call the #include COMPARE_M macro. The Apache Shiro 1 comp kernel is shown below.
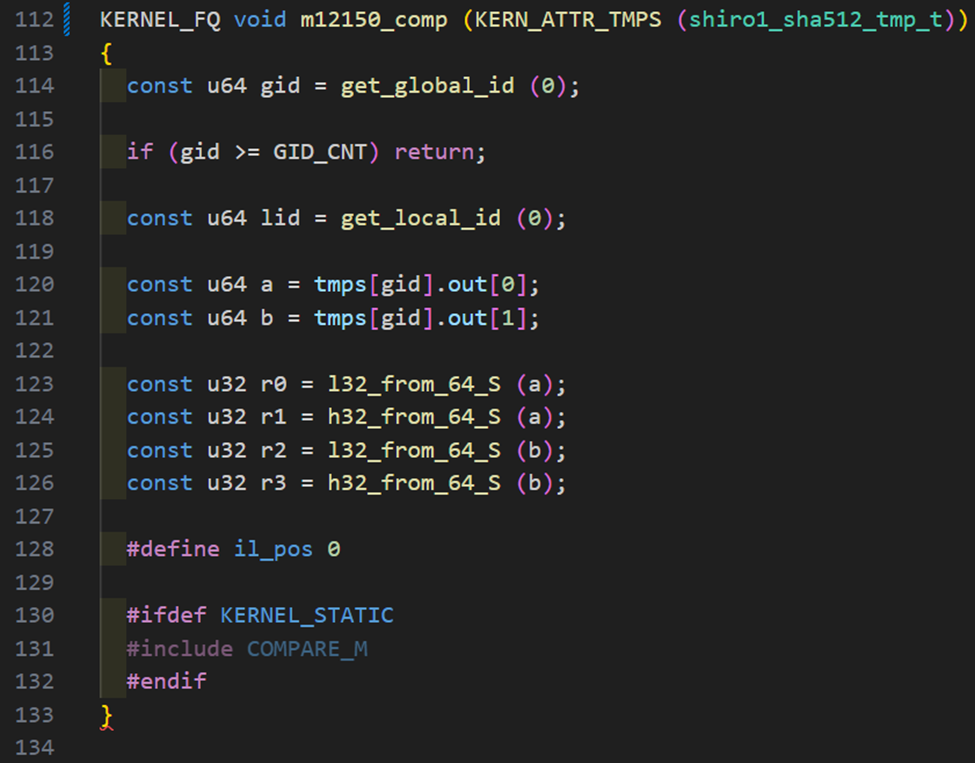
As you can see, we convert the final digest contained in out of tmps to u32 (or as much of it as can fit in the four comparison variables) and then call the COMPARE_M macro which will do the bloom filter comparison along with an additional binary tree search for light speed comparisons. At this point, we are done creating the kernel and the module and it is ready for use!
Testing the Module
Test Suite Background
Once we have our module kernel and C code put together and we believe we are ready to test it, Hashcat comes with its own testing mechanism called the Test Suite. A snippet of the documentation for the Test Suite can be seen below. The Test Suite is explained in detail at the provided link, but the idea is to provide a way to ensure that a module is working correctly (both the C code and OpenCL kernel).
This is done by using a higher-level programming language, in this case Perl, to perform the cryptographic operations. The Test Suite can either test cracking data generated by the test module with the low-level module or verify that the reported cracked data from the low-level module is accurate. While everyone has a different level of knowledge when it comes to cryptography and programming, cryptographic implementations between two programming languages are the same. This means that although the code will look different due to the different syntax of the programming languages, the actual cryptographic operations on the data will remain the same.
Why is this a good testing strategy? If we can verify that we can crack data generated by the Perl test module, it is highly likely that our cryptographic operations in our kernel are accurate and true to the algorithm. Additionally, we can conclude that our methods in the module C code are working as expected, providing a way to test the entire module.
Before we continue, let’s discuss the test scripts which automate the testing process. Throughout this process, you are going to be working closely with two scripts which are test.pl and test.sh. The test.sh script comes with different command line arguments that allow you to change the behavior of testing and automates most of the testing process by executing Hashcat commands generated by test.pl. You can think of it as a wrapper around test.pl. Everything except verify tests will be automated by test.sh.
Perl Test Module Development
As you can see in the screenshot above, there are three methods our test module must implement and they are module_constraints, module_generate_hash, and module_verify_hash. There is more documentation for test modules and an explanation of these methods is provided below.
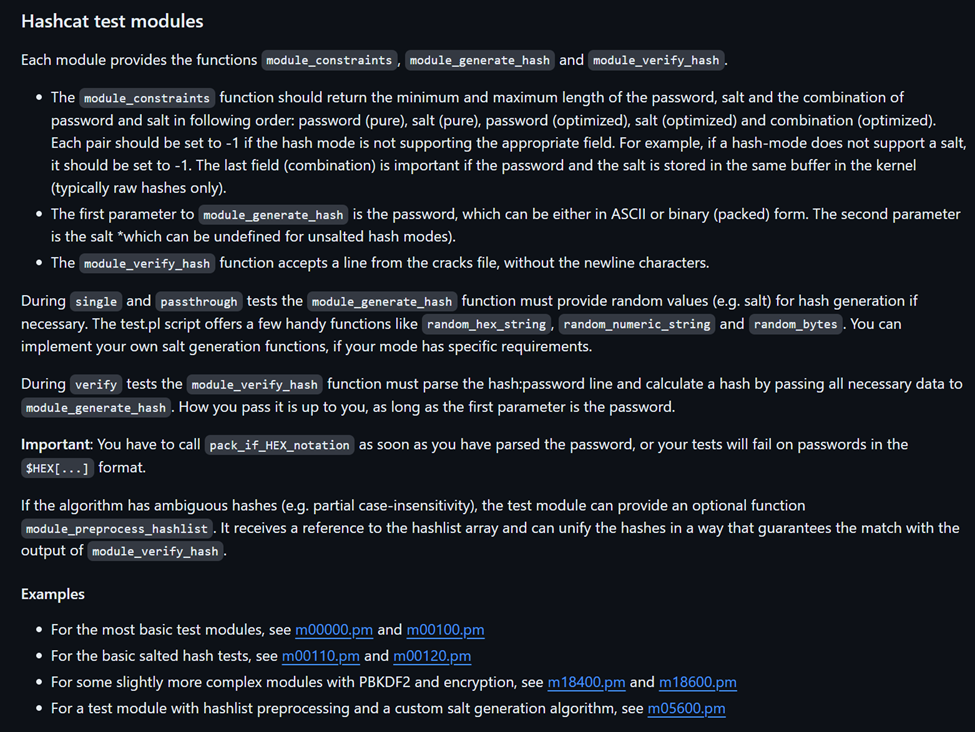
As you can see, this documentation provides links to various Perl modules that you can look at as examples. I encourage you to try to find a module that is closest to the module you are trying to create as that will contain the most relevant example code. The module_constraints to module_generate_hash implementations for our module can be seen below.

As shown above, module_constraints returns the minimum and maximum length for a password hashed using this algorithm as well as the size for generated salts, which is 16 bytes. Also shown is module_generate_hash, which takes three arguments being: a password to hash, the salt to use for the hash, and the number of iterations to perform on the hash. It then generates a hash using these arguments and returns it, which will be used as part of testing with test.sh/test.pl. This method should generate a hash for your algorithm, preferably using Perl cryptography libraries and the arguments passed to the method. The arguments that are passed are controlled by the test.pl/test.sh programs and based on which test is being performed. It is important to make sure your Perl implementation is accurate according to the specification for the algorithm, otherwise all your testing will be inaccurate. You should test it independently from Hashcat and verify generated hashes are accurate and make sure your logic for module_verify_hash is working correctly before performing a test with the Test Suite.
Running test.sh
At this point, we are ready to run test.sh to test cracking using the module and will focus on module_verify_hash later. If you are a Windows user developing/testing your module on a Windows host, you might have been like me at the beginning of this process and had a reaction similar to the one below regarding the test.sh script.

No need to fear though as we can still test our module on Windows using WSL/WSL2 or Cygwin using the test.sh script and providing “win” for the -o flag. Our command line for running test.sh is displayed below.

Here is an explanation of these flags and their values:
· -m 12150: specifically test using the m12150.pm test module
· -a all: test all attack modes
· -t all: test single and multi hash modes
· -P: use pure kernels instead of optimized kernels since our module’s kernel is pure without an optimized version
· -o win: use the Windows operating system (adds .exe file extension to Hashcat binary to run with WSL/WSL2/Cygwin)
The output shown in our screenshot from the test.sh script indicates success for all tests. Since everything was found/matched and nothing timed out or was skipped, all tests passed. A success from this test command means the module was able to successfully crack hashes generated by the Perl test module. If you were getting results showing hashes were not found/matched, timeouts, or hashes being skipped, these would be indicators of failed tests. Now onto the module_verify_hash method.
Running Verify Test
Since we require a sample of cracked hashes to perform verify tests, they are not automated by test.sh and are run post-crack. The flow for performing a verify test would be to: generate known hashes, crack them to a pot file, and then run test.pl in verify mode while supplying the hash file, hash mode, pot file, and output file as arguments. The purpose of this test is to verify if cracked hashes are being accurately marked. Our implementation for module_verify_hash is shown below.
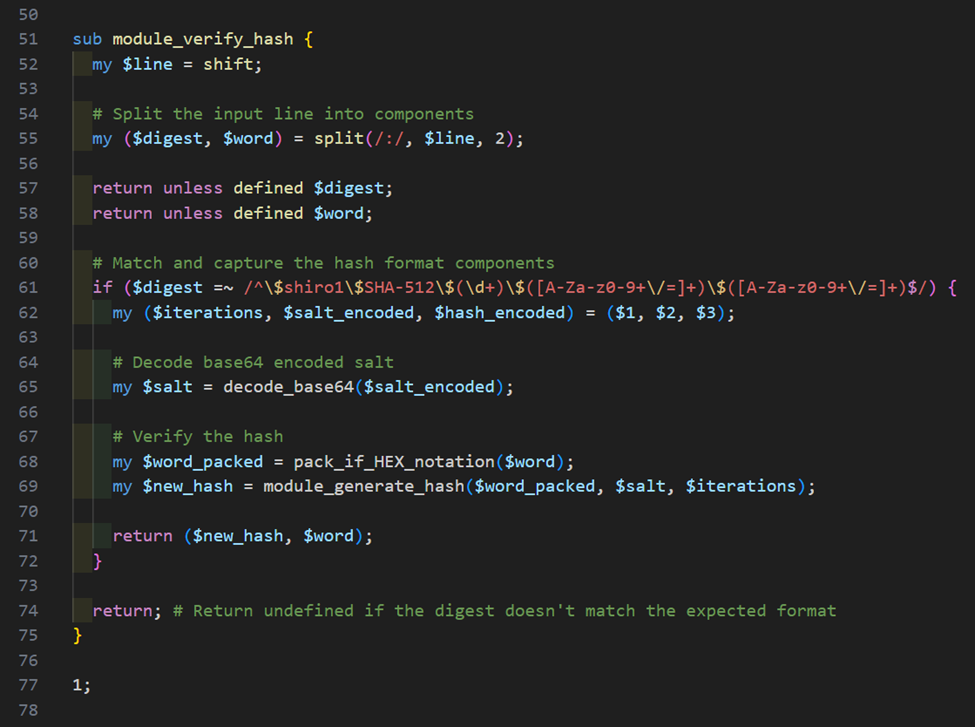
As you can see, it will take a line from the pot file and extract the password, salt, and number of iterations from it. From there, it will generate a new hash using module_generate_hash. Next, test.pl will perform a comparison of the newly generated hash against all hashes in the original hash file. If there is not a match, it is an indicator that the module is reporting false positives for cracked hashes and there is likely an issue with the comp method of your kernel. Below is an example of generating hashes to be cracked and used for a verify test using shiro-hash-generator.
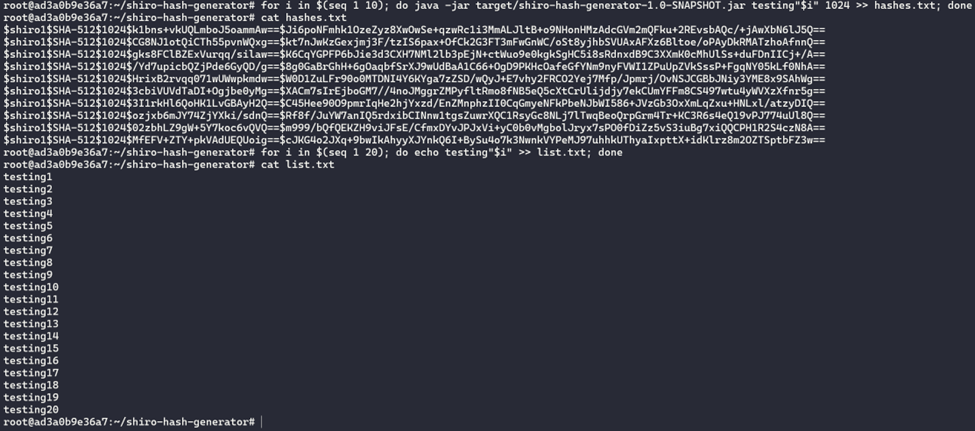
We can then perform the crack using the command below.
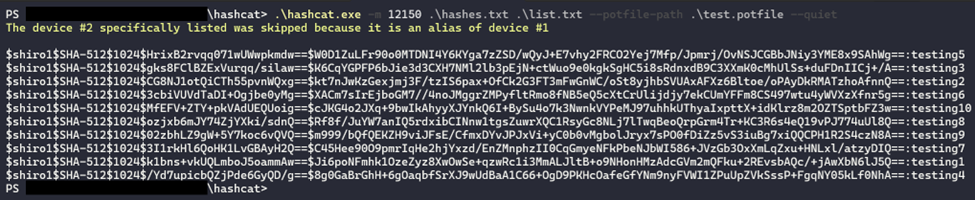
Following this command, the crack results will be stored in test.potfile in <DIGEST>:<PASSWORD> format. We can then perform our verify test with test.pl which is shown below.

Looking at the documentation for verify above, we can see that if a hash in the pot file matches an entry in the hashes file, it will be written to the out file indicating a successful verification. After running test.pl, the contents of log.txt are displayed, which contains all of our pot file entries. This result indicates a successful test and that our module is accurately marking hashes as cracked. This concludes testing our module using the Hashcat Test Suite!
Conclusion

From Weeks to Hours: Hashcat Module Performance
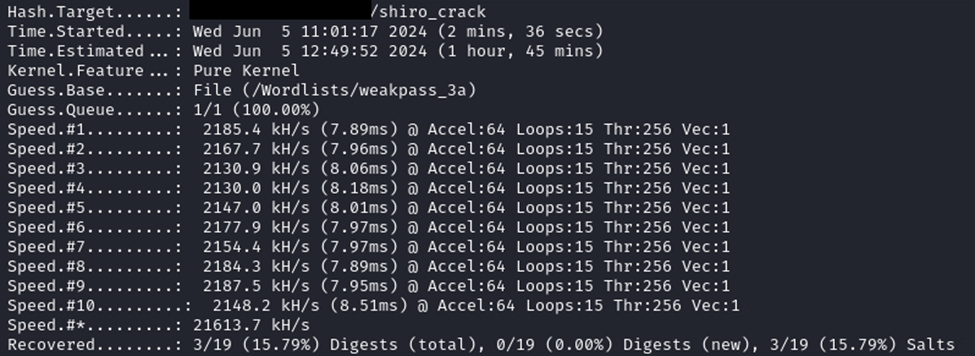
When we discuss performance of the Hashcat module versus the standalone C implementation, the weakpass_3a wordlist was going to take multiple weeks for one hash to complete after modifying the C program to take an input hash as a commandline argument. The hash cracking rig we are using (which has 10 NVIDIA RTX 3090’s) was able to perform a crack using the same wordlist against 16 hashes in 1 hour and 45 minutes with a speed of testing hashes at 21613.7 kH/s (21,613,700 per second) using the Hashcat module.
Takeaways

Overall, there are some key pieces of information to take away here:
- The Apache Shiro 1 SHA-512 hashing algorithm used to have a limited attack surface due to the lack of Hashcat support or similar project that can utilize GPU hardware to crack the algorithm; this is no longer true.
- Sonatype’s default iteration count is relatively low at 1024 iterations per hash and is actually below the Apache Shiro default iteration, making it a fairly inexpensive algorithm with decent cracking times.
- Sonatype hashes user credentials for the web application database using this algorithm, if a system is vulnerable to a LFI/path traversal (i.e. CVE-2024–4956) vulnerability, you can extract these hashes from OrientDB .pcl files and then crack them with the Hashcat module. Any other means of gaining access to these files is valid such as compromising a system where these files have been backed up, compromising a system through a different vulnerability, etc.
- We learned how to create a moderately complex Hashcat module as well as where to find the official documentation for plugin development that can be applied to different algorithms if we come across a situation such as this in the future. We also learned how to test our module to make sure it is working correctly.

The advice I will give at the end of this piece of writing is to keep calm and hack the planet!